Description
Sometime in 2019 after graduating I found myself in need of a job. I built a simple web scraping bot in a jupyter notebook over a weekend to help me find good roles quicker, and cut through some of the crud. To help with this, I made it parse through job descriptions and titles on Indeed, rank them according to the presence of certain keywords, and produce a condensed spreadsheet with any relevant information. Not too long after that I converted it into the simple webapp, hosted below.
The underlying scraper is written in Python using the web interaction libraries Beautiful Soup and Requests. The front end of the web app is written in Python using Dash and the entire thing is hosted on a Heroku server.
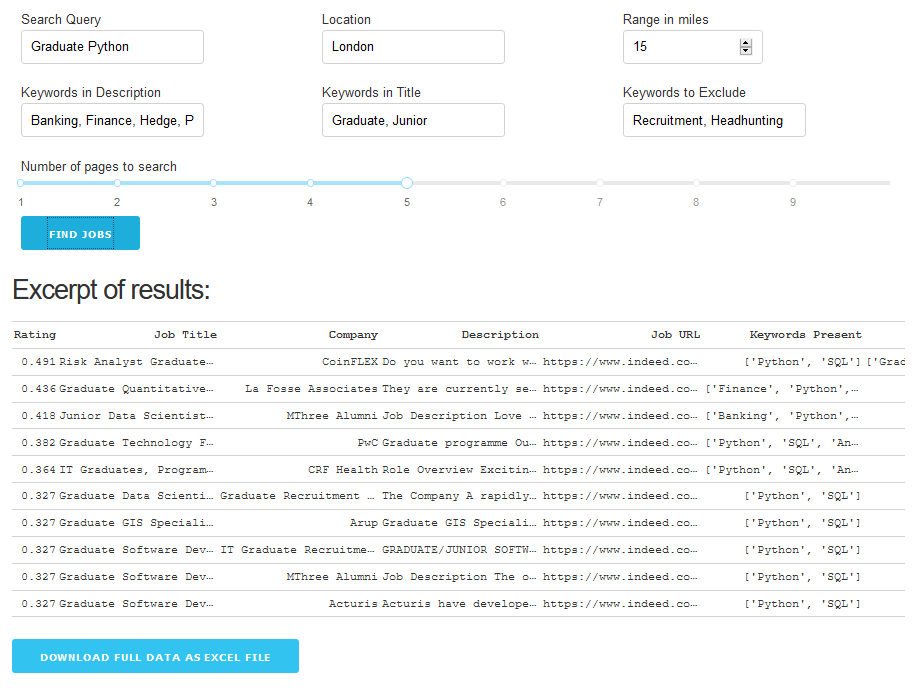
By the miracle of Indeed’s stable and unchanging website structure the app remained functional for about a year with no further time investment on my part (much longer than I anticipated). Typical output for the scraper looked like the following:
Example Output
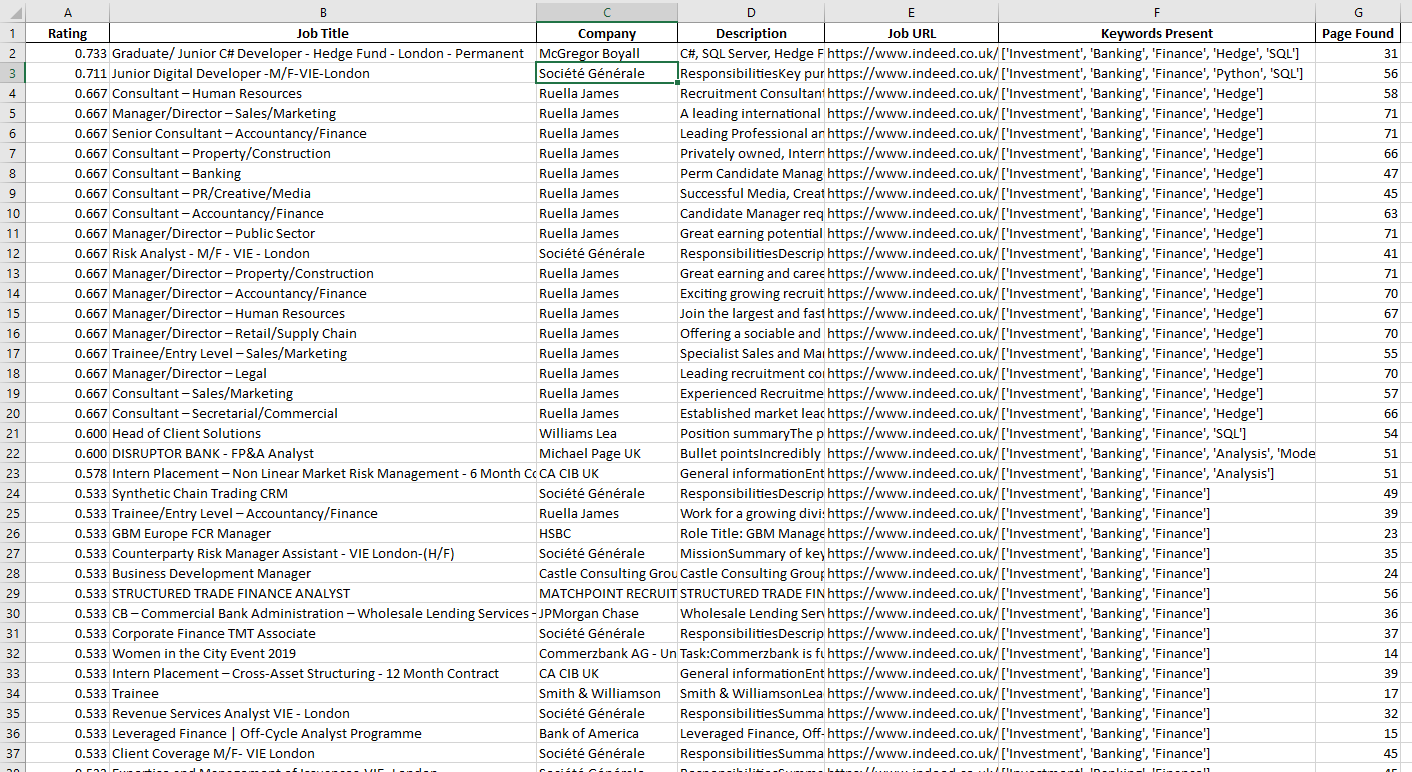
Example Excel Output
Below you can find an instance of the app running on a heroku server somewhere in the cloud.